- Table de hashage
-
Table de hachage
En informatique, une table de hachage est une structure de données qui permet une association clé-élément, c'est-à-dire une implémentation du type abstrait table de symboles.
On accède à chaque élément de la table via sa clé. Il s'agit d'un tableau ne comportant pas d'ordre (un tableau est indexé par des entiers). L'accès à un élément se fait en transformant la clé en une valeur de hachage (ou simplement hachage) par l'intermédiaire d'une fonction de hachage. Le hachage est un nombre qui permet la localisation des éléments dans le tableau, typiquement le hachage est l'index de l'élément dans le tableau. Une case dans le tableau est appelée alvéole.
 In annuaire représenté comme une table de hachage.
In annuaire représenté comme une table de hachage.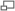
Tout comme les tableaux, les tables de hachage permettent un accès en O(1) en moyenne, quel que soit le nombre d'éléments dans la table. Toutefois le temps d'accès dans le pire des cas peut être de O(n). Comparées aux autres tableaux associatifs, les tables de hachage sont surtout utiles lorsque le nombre d'entrées est très important.
La position des éléments dans une table de hachage est pseudo-aléatoire. Cette structure n'est donc pas adaptée pour accéder à des données triées. Des types de structures de données comme les arbres équilibrés sont généralement plus lents (en O(log n)) et sont plus complexes à implémenter mais maintiennent une structure ordonnée.
Le fait de créer un hash à partir d'une clé peut engendrer un problème de collision, c’est-à-dire qu'à partir de deux clés différentes, la fonction de hachage pourrait renvoyer la même valeur de hash, et donc par conséquent donner accès à la même position dans le "tableau". Pour minimiser les risques de collisions, il faut donc choisir soigneusement sa fonction de hachage.
Sommaire
Choix d'une bonne fonction de hachage
Une bonne fonction de hachage est cruciale pour les performances. Les collisions étant en général résolues par des méthodes de recherche linéaire, une mauvaise fonction de hachage, i.e. produisant beaucoup de collisions, va fortement dégrader la rapidité de la recherche. D'autre part, il est préférable que la fonction de hachage ne soit pas de complexité élevée.
Le calcul du hachage se fait parfois en 2 temps :
- Une fonction de hachage particulière à l'application est utilisée pour produire un nombre entier à partir de la donnée d'origine.
- Ce nombre entier est converti en une position possible de la table, en général en calculant le reste modulo la taille de la table.
Les tailles des tables de hachage sont souvent des nombres premiers, afin d'éviter les problèmes de diviseurs communs, qui créeraient un nombre important de collisions. Une alternative est d'utiliser une puissance de deux, ce qui permet de réaliser l'opération modulo par de simples décalages, et donc de gagner en rapidité.
Un problème fréquent et surprenant est le phénomène de clustering qui désigne le fait que des valeurs de hachage se retrouvent côte à côte dans la table, formant des clusters. Ceci est très pénalisant pour les techniques de résolution des collisions par adressage ouvert. Les fonctions de hachage réalisant une distribution uniforme des hachages sont donc les meilleures, mais sont en pratique difficile à trouver.
Dans les environnements où un adversaire essaye d'attaquer les performances de la recherche en soumettant des entrées générant un grand nombre de collisions afin de ralentir la recherche, une solution est le hashing universel, qui sélectionne aléatoirement une fonction de hachage au début de l'algorithme. L'adversaire n'a alors pas de moyen de connaitre le type de données qui produira des collisions.
Résolution des collisions
Lorsque deux clés ont la même valeur de hachage, ces clés ne peuvent être stockées à la même position, on doit alors employer une stratégie de résolution des collisions.
Pour donner une idée de l'importance d'une bonne méthode de résolution des collisions, considérons ce résultat issu du paradoxe des anniversaires. Même si nous sommes dans le cas le plus favorable où la fonction de hachage a une distribution uniforme, il y a 95% de chances d'avoir une collision dans une table de taille 1 million avant qu'elle ne contienne 2500 éléments.
De nombreuses stratégies de résolution des collisions existent mais les plus connues et utilisées sont le chainage et l'adressage ouvert.
Chaînage
 Résolution des collisions par chaînage.
Résolution des collisions par chaînage.Cette méthode est la plus simple. Chaque case de la table est en fait une liste chaînée des clés qui ont le même hachage. Une fois la case trouvée, la recherche est alors linéaire en la taille de la liste chaînée. Dans le pire des cas où la fonction de hachage renvoie toujours la même valeur de hachage quelle que soit la clé, la table de hachage devient alors une liste chaînée, et le temps de recherche est en O(n). L'avantage du chaînage est que la suppression d'une clé est facile, et que l'agrandissement de la table peut être retardé plus longtemps que dans l'adressage ouvert, les performances se dégradant moins vite.
D'autres structures de données que les listes chaînées peuvent être utilisées. En utilisant un arbre équilibré le coût théorique de recherche dans le pire des cas est en O(log n). Cependant, la liste étant supposée être courte, cette approche est en général peu efficace à moins d'utiliser la table à sa pleine capacité, ou d'avoir un fort taux de collisions. Un tableau dynamique peut aussi être utilisé pour réduire la perte d'espace mémoire et améliorer les performances du cache lorsque le nombre d'éléments est petit.
Adressage ouvert
 Résolution des collisions par adressage ouvert et sondage linéaire.
Résolution des collisions par adressage ouvert et sondage linéaire.L'adressage ouvert consiste dans le cas d'une collision à stocker les valeurs de hachage dans des cases contigües. La position de ces cases est déterminée par une méthode de 'sondage'. Lors d'une recherche, si la case obtenue par hachage direct ne permet pas d'obtenir la bonne clé, une recherche sur les cases obtenues par une méthode de sondage est effectuée jusqu'à trouver la clé, ou non, ce qui indique qu'aucune clé de ce type n'appartient à la table.
Les méthodes de sondage courantes sont:
- Sondage linéaire
- l'intervalle entre les cases est fixe, souvent 1.
- Sondage quadratique
- l'intervalle entre les cases augmente linéairement (les indices des cases augmentent donc quadratiquement)
Ce qui peut s'exprimer par la formule :
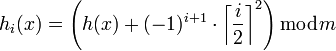
- Double hachage
- l'adresse de la case est donnée par une deuxième fonction de hachage, ou hachage secondaire.
Le sondage linéaire possède la meilleure performance en termes de cache mais est sensible à l'effet de clustering décrit plus haut. Le double hachage ne permet pas d'utiliser le cache efficacement mais permet de réduire presque complètement les problèmes de clustering, en contrepartie d'une complexité plus élevée. Le sondage quadratique se situe entre le linéaire et le double hashing au niveau des performances.
Une indication critique des performances d'une table de hachage est le facteur de charge qui est la proportion de cases utilisées dans la table. Plus le facteur de charge est proche de 100%, plus le nombre de sondages à effectuer devient important. Lorsque la table est pleine, les algorithmes de sondage peuvent même échouer. Le facteur de charge est en général limité à 80%, même en disposant d'une bonne fonction de hachage. Des facteurs de charge faibles ne sont pas pour autant significatifs de bonne performances, en particulier si la fonction de hachage est mauvaise et génère du clustering.
Hachage probabiliste
Modification de la taille de la table
Fonction de Hachage
Une fonction de hachage permet de transformer une clé en une valeur de hachage (un index), donnant ainsi la position d'un élément dans le tableau. Si la clé n'est pas un entier naturel, il faut trouver un moyen de la considérer comme un entier naturel. Par exemple, si la clé est de type Chaine de caractères, on peut ajouter la position dans l'alphabet de chaque lettre pour obtenir un entier naturel. Il suffit ensuite de transformer cet entier en index par différentes façons. Par exemple, en prenant le reste de la division de l'entier par le nombre d'éléments dans le tableau.
Voici l'une des fonctions de hachage les plus puissantes écrite par Daniel J. Bernstein[réf. nécessaire] (en langage C) :
unsigned long hash(unsigned char *str) { unsigned long hash = 5381; while(*str!='\0') { int c = *str; /* hash = hash*33 + c */ hash = ((hash << 5) + hash) + c; str++; } return hash; }
Références
- Donald Knuth. The Art of Computer Programming, Volume 3: Sorting and Searching, Third Edition. Addison-Wesley, 1997. ISBN 0-201-89685-0. Section 6.4: Hashing, pp.513–558.
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Chapter 11: Hash Tables, pp.221–252.
- Michael T. Goodrich and Roberto Tamassia. Data Structures and Algorithms in Java, 4th edition. John Wiley & Sons, Inc. ISBN 0-471-73884-0. Chapter 9: Maps and Dictionaries. pp.369–418
- Christine Froidevaux, Marie-Claude Gaudel et Michèle Soria, Types de données et algorithmes, McGraw-Hill, Collection Informatique, 1990, 575 pages.
 Portail de l’informatique
Portail de l’informatique
Catégorie : Hachage



Wikimedia Foundation. 2010.