- Entropie De Shannon
-
Entropie de Shannon
L'entropie de Shannon, due à Claude Shannon, est une fonction mathématique qui, intuitivement, correspond à la quantité d'information contenue ou délivrée par une source d'information. Cette source peut être un texte écrit dans une langue donnée, un signal électrique ou encore un fichier informatique quelconque (collection d'octets). Du point de vue d'un récepteur, plus la source émet d'informations différentes, plus l'entropie (ou incertitude sur ce que la source émet) est grande, et vice versa. Plus le récepteur reçoit d'information sur le message transmis, plus l'entropie (incertitude) vis-à-vis de ce message décroît, en lueur de ce gain d'information. La définition de l'entropie d'une source selon Shannon est telle que plus la source est redondante, moins elle contient d'information. En l'absence de contraintes particulières, l'entropie est maximale pour une source dont tous les symboles sont équiprobables.
Dans le cas particulier d'un système de télécommunication, l'entropie de la source d'information (le transmetteur) indique l'incertitude du récepteur par rapport à ce que la source va transmettre. Par exemple, une source réputée envoyer toujours le même symbole, disons la lettre 'a', a une entropie nulle, c'est-à-dire minimale. En effet, un récepteur qui connait seulement les statistiques de transmission de la source est assuré que le prochain symbole sera un 'a', sans jamais se tromper. Le récepteur n'a pas besoin de recevoir de signal pour lever l'incertitude sur ce qui a été transmis par la source car celle-ci n'engendre pas d'aléa. Par contre, si la source est réputée envoyer un 'a' la moitié du temps et un 'b' l'autre moitié, le récepteur est incertain de la prochaine lettre à recevoir. L'entropie de la source dans ce cas est donc non nulle (positive) et représente quantitativement l'incertitude qui règne sur l'information émanant de la source. Du point de vue du récepteur, l'entropie indique la quantité d'information qu'il lui faut obtenir pour lever complètement l'incertitude (ou le doute) sur ce que la source a transmis.
Sommaire
Historique
En 1948, tandis qu'il travaillait aux Laboratoires Bell, l'ingénieur en génie électrique Claude Shannon formalisa mathématiquement la nature statistique de "l'information perdue" dans les signaux des lignes téléphoniques. Pour ce faire, il développa le concept général d'entropie de l'information, fondamental dans la théorie de l'information[1].
Initialement, il ne semble pas que Shannon ait été particulièrement au courant de la relation étroite entre sa nouvelle mesure et les travaux précédents en thermodynamique. Le terme entropie a été suggéré par le mathématicien John von Neumann pour la raison que cette notion ressemblait à celle déjà connue sous le nom d'entropie en physique statistique, et il aurait ajouté que ce terme était de plus assez mal compris pour pouvoir triompher dans tout débat[2].
En 1957, Edwin Thompson Jaynes démontrera le lien formel existant entre l'entropie macroscopique introduite par Clausius en 1847, la microscopique introduite par Gibbs, et l'entropie mathématique de Shannon. Cette découverte fut qualifié par Myron Tribus de "révolution passée inaperçue"[3].
Préambule
Au début des années 1940, les télécommunications étaient dominées par l'analogique. La transmission radio ainsi que la télévision reposaient sur des modulations continues comme la modulation d'amplitude (AM) et la modulation en fréquence (FM). Les sons et les images étaient transformés en signaux électriques dont l'amplitude et/ou la fréquence sont des fonctions continues, parfois proportionnelles, au signal d'entrée. Dans le cas du son, nous mesurons à l'aide d'un microphone le phénomène de pression et de dépression voyageant dans l'air. Dans le cas de la télévision, la blancheur de l'image (sa luminosité) est le principal signal d'intérêt. Cette procédure implique qu'un bruit ajouté pendant la transmission résultait en une dégradation du signal reçu. L'archétype de ce type de bruit prend la forme de grésillement pour la radio et de neige pour la télévision. La modulation analogique implique l'utilisation des nombres réels dont l'expansion décimale est infinie pour représenter une information (pression sonore, intensité lumineuse, etc.). Un bruit, aussi infime soit-il, a donc une conséquence directe sur le signal.
Les chercheurs ont donc admis qu'une façon efficace de se prémunir du bruit serait de transformer le son et l'image en nombres discrets, plutôt que d'utiliser des nombres réels dont la précision requiert un nombre infini de chiffres. On pourrait par exemple convenir d'utiliser le nombre 0 pour représenter la noirceur totale et le nombre 10 pour un blanc parfait, avec tous les nombres entiers entre les deux représentant des niveaux successifs de gris. Si 11 niveaux ne paraissent pas suffisants, nous pouvons utiliser la même méthode pour un nombre de division des intensités aussi grand que nécessaire pour satisfaire l'oeil. Un raisonnement similaire peut être effectué pour le son et nous arrivons à un point où il est possible de représenter un film et sa trame sonore avec une quantité finie de nombres entiers.
La transmission de ces nombres entiers résulte en ce que nous appelons une communication numérique. Si le bruit dont nous avons parlé dans le cas analogique est considéré dans une transmission numérique, des erreurs se produiront lorsque ce bruit sera suffisamment fort pour transformer un nombre en un autre. Dans le cas analogique, même un petit bruit se transforme en erreurs perceptibles. En numérique, un petit bruit a peu de chances de produire une erreur, mais un bruit suffisant peut toutefois le faire. Les chercheurs ont longtemps pensé qu'il fallait se résoudre à accepter qu'une communication parfaite était impossible. C'est cette conjoncture que Shannon devait réfuter par sa théorie de l'information. Il devait montrer qu'il était possible de transmettre des informations sans erreur en utilisant une stratégie de codage numérique en autant que nous nous contentions d'une certaine vitesse de transmission. On entend ici par sans erreur la capacité du récepteur à restaurer le message original même si le message reçu est modifié par le bruit.
L'entropie de Shannon, mesure du contenu informationnel d'un message, intervient alors conjointement aux théorèmes de Shannon pour décider de la vitesse à ne pas dépasser si nous voulons avoir espoir de transmettre les données de ce message sans erreur. Il va de soi qu'un bruit plus puissant altère davantage un message transmis et Shannon prédit qu'en présence d'un bruit plus important il faut réduire la vitesse de transmission pour arriver au même résultat sans erreur. Une stratégie de codage élémentaire est la transmission multiple de la même information. En effet, la probabilité d'obtenir des erreurs sur la majorité de ces informations est plus basse que la probabilité d'obtenir une erreur pour une transmission unique. Ceci constitue toutefois un codage naïf et ne permet pas d'atteindre les limites posées par Shannon.
Le calcul de l'entropie d'une source de messages donne une mesure de l'information minimale que nous devons conserver afin de représenter ces donnnés sans perte. En termes communs, cela signifie pour le cas particulier de la compression de fichiers en informatique que l'entropie indique le nombre minimal de bits que peut atteindre un fichier compressé. Il faut comprendre que si nous sommes disposés à perdre des données, comme lors de la compression des sons par le format MP3 ou lors de la compression d'images par JPEG ou des vidéos par MPEG, nous pouvons franchir cette limite inférieure imposée par l'entropie de l'image originale. En réalité, nous abaissons d'abord l'entropie de l'image ou du son en retirant des détails imperceptibles pour les humains. La nouvelle entropie réduite est alors la nouvelle limite inférieure pour la compression sans perte subséquente.
Définition formelle
Pour une source, qui est une variable aléatoire discrète, X comportant n symboles, un symbole i ayant une probabilité pi d'apparaître, l'entropie H de la source X est définie comme :
où
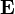 désigne l'espérance mathématique. On utilise en général un logarithme à base 2 car l'entropie possède alors les unités de bits/symbole. Les symboles représentent les réalisations possibles de la variable aléatoire X.
désigne l'espérance mathématique. On utilise en général un logarithme à base 2 car l'entropie possède alors les unités de bits/symbole. Les symboles représentent les réalisations possibles de la variable aléatoire X.L'entropie ainsi définie vérifie les propriétés suivantes :
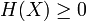 avec égalité ssi
avec égalité ssi 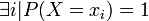
- elle est supérieure ou égale à zéro, avec égalité pour une distribution résumée en un point, c'est à dire nulle en tout point i sauf en un point i * pour lequel p(i * ) = 1 ;
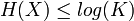 où K est le nombre d'éléments de X
où K est le nombre d'éléments de X
- elle est maximale pour une distribution uniforme, c’est-à-dire quand tous les états ont la même probabilité ;
- toutes choses égales par ailleurs, elle augmente avec le nombre d'états possible (ce qui traduit l'intuition que plus il y a de choix possibles, plus l'incertitude est grande) ;
- elle est continue
Justification du logarithme
L'utilisation du logarithme peut paraître arbitraire à première vue. Il faut se souvenir que l'effet du logarithme est de transformer la multiplication en addition et la division en soustraction. Par ailleurs, étant donné deux variables aléatoires indépendantes X et Y, la probabilité du produit cartésien de ces variables aléatoires est donnée par :
Ainsi:
Ce qui est intuitivement satisfaisant puisque X et Y sont indépendantes. L'entropie étant une mesure d'information moyenne contenue dans une variable aléatoire, l'entropie de la combinaison de deux variables qui ne sont pas reliées entre-elles s'additionne simplement. On voit alors le travail qu'effectue le logarithme en effectuant le pont entre la multiplication des probabilités et l'addition des entropies. Dans le cas où il existe une certaine dépendance entre X et Y, on vérifie par une preuve semblable que :
Maximisation de l'entropie
Inégalité de Gibbs
La proposition précédente, suivant qu'une distribution d'événements équiprobables maximise l'entropie pour un nombre donné d'éléments K, peut être exprimée plus généralement par l'inégalité de Gibbs :
où qi est une distribution de probabilités quelconque sur la variable X. On voit alors que l'inégalité précédente est obtenue en tant que cas particulier lorsque 1 / qi = K, c'est-à-dire pour des événements équiprobables :
Démonstrations
Preuve par l'inégalité de Jensen
Le logarithme est une fonction concave, c'est-à-dire que sa dérivée seconde est inférieure ou égale à zéro pour toute valeur de x sur son domaine. Par Jensen nous obtenons alors :
Puis en posant :
En substituant dans Jensen :
Et en développant les espérances mathématiques :
Par la propriété des logarithmes :
CQFD.
Preuve par une borne linéaire sur le logarithme
Il est facile de vérifier que la fonction logarithmique est bornée supérieurement par n'importe quelle droite tangente à celle-ci. La nature concave de la fonction logarithme lui confère cette propriété :
On a ainsi :
La fin de la preuve est la même que précédemment, par la propriété des logarithmes :
CQFD.
Propriétés
Voici quelques propriétés importantes de l'entropie de Shannon :
Utilité pratique
L'entropie de Shannon est utilisée en électronique numérique pour numériser une source en utilisant le minimum possible de bits sans perte d'information. Elle permet aussi de quantifier le nombre minimum de bits sur lesquels on peut coder un fichier, mesurant ainsi les limites que peuvent espérer atteindre les algorithmes de compression sans perte. Elle est également utilisée dans d'autres domaines, comme, par exemple, pour la sélection du meilleur point de vue d'un objet en trois dimensions[4].
Exemples simples
Urnes
Considérons une urne contenant plusieurs boules de différentes couleurs, dont on tire une boule au hasard (avec remise). Si toutes les boules ont des couleurs différentes, alors notre incertitude sur le résultat d'un tirage est maximale. En particulier, si nous devions parier sur le résultat d'un tirage, nous ne pourrions pas privilégier un choix plutôt qu'un autre. Par contre, si une certaine couleur est plus représentée que les autres (par exemple si l'urne contient davantage de boules rouges), alors notre incertitude est légèrement réduite : la boule tirée a plus de chances d'être rouge. Si nous devions absolument parier sur le résultat d'un tirage, nous miserions sur une boule rouge. Ainsi, révéler le résultat d'un tirage fournit en moyenne davantage d'information dans le premier cas que dans le second, parce que l'entropie du "signal" (calculable à partir de la distribution statistique) est plus élevée.
Texte
Prenons un autre exemple : considérons un texte en français codé comme une chaîne de lettres, d'espaces et de ponctuations (notre signal est donc une chaîne de caractères). Comme la fréquence de certains caractères n'est pas très importante (ex : 'w'), tandis que d'autres sont très communs (ex : 'e'), la chaîne de caractères n'est pas si aléatoire que ça. D'un autre côté, tant qu'on ne peut pas prédire quel est le caractère suivant, d'une certaine manière, cette chaîne est aléatoire, ce que cherche à quantifier la notion d'entropie de Shannon.
Voir aussi
- Complexité de Kolmogorov
- Entropie de Rényi
- Entropie métrique
- Entropie différentielle
- Information mutuelle
- Théorie de l'information
Bibliographie
- ↑ Claude E.Shannon A mathematical theory of communication Bell System Technical Journal, vol. 27, pp. 379-423 and 623-656, July and October, 1948
- ↑ M. Tribus, E.C. McIrvine, “Energy and information”, Scientific American, 224 (September 1971).
- ↑ La référence est dans ce document (PDF)
- ↑ (en) P.-P. Vàzquez, M. Feixas, M. Sbert, W. Heidrich, Viewpoint selection using viewpoint entropy, Proceedings of the Vision Modeling and Visualization Conference, 273-280, 2001.
 Portail de l’informatique
Portail de l’informatique Portail des mathématiques
Portail des mathématiques
Catégorie : Théorie de l'information -
![H_b(X)= -\mathbf E [\log_b {P(X=x_i)}] = \sum_{i=1}^nP_i\log_b \left(\frac{1}{P_i}\right)=-\sum_{i=1}^nP_i\log_b P_i.\,\!](/pictures/frwiki/99/cbd6017f6595705730de32b0f8142582.png)
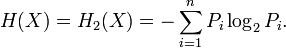
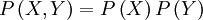
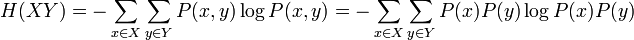
![\Rightarrow H(XY)=-\sum_{x \in X}\sum_{y \in Y} P(x)P(y)\left[\log P(x) + \log P(y)\right]](/pictures/frwiki/55/70a65de589c277fd796055a6447a8df5.png)
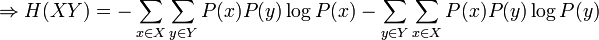
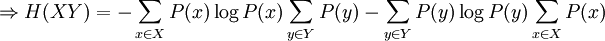
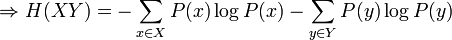
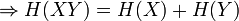
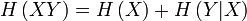
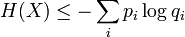
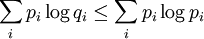
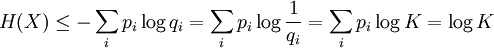
![E[f(X)] \leq f(E[X])](/pictures/frwiki/55/785ba5bab8d7fb99157372f9181345f3.png)
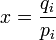
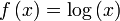
![E\left[\log \frac{q_i}{p_i}\right] \leq \log \left(E\left[\frac{q_i}{p_i}\right]\right)](/pictures/frwiki/99/ce8002e51230f1f343b06ac2f0b60993.png)
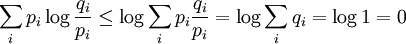
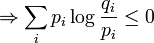
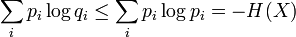
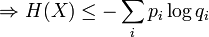
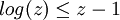
![\sum_i p_i \log \frac{q_i}{p_i} \leq \sum_i p_i \left[ \frac{q_i}{p_i} - 1 \right]=\sum_i \left[q_i - p_i \right]=\sum_i q_i - \sum_i p_i=1-1=0](/pictures/frwiki/102/fdc377e1f3cf635f9bb5f66a52dc7083.png)
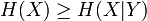
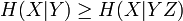
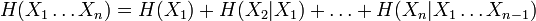
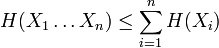
Wikimedia Foundation. 2010.