- Fault tolerance
-
Tolérance aux pannes
Le concept de tolérance aux pannes se réfère à une méthode de conception d'un système de telle façon qu'il puisse continuer à fonctionner, potentiellement de manière réduite, au lieu de tomber complètement en panne dès que l'un de ses composants ne fonctionne plus correctement.
Noter la différence entre :
- les systèmes informatiques conçus pour ne pratiquement pas être ralentis en cas de défaillance matérielle ou logicielle ;
- les critères définis pour représenter la fiabilité.
Un exemple hors de l'informatique est un véhicule conçu pour être toujours conduisible même si l'un des pneus est crevé.
Critères de tolérance aux pannes
Aucune machine, y compris en électronique et en informatique, n'est fiable à 100 %, ni inusable. Le fabricant, ou un laboratoire d'essais indépendant, définit, après des tests traduisant une utilisation plus ou moins sévère, un critère de tolérance aux pannes de ladite machine.
Ce critère s'exprime soit en un nombre moyen d'heures entre panne (en anglais MTBF, ou mean time between failure), soit en un nombre d'heures de fonctionnement avant la fin de vie de la machine. On lui associe en général un autre paramètre, le MTTR (mean time to repair), le temps moyen de réparation. La combinaison des deux permet d'établir le taux de disponibilité prévisible.
La disponibilité correspond à
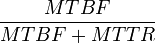 .
.Degrés de gravité des défaillances
- panne franche (« fail stop ») : soit le système fonctionne normalement (les résultats sont corrects), soit il ne fait rien. Il s'agit du type de panne le plus simple ;
- panne par omission ou panne transitoire : des messages sont perdus en entrée ou en sortie ou les deux. Elle est considérée comme une panne temporelle de durée infinie ;
- panne temporelle : le temps de réponse du système dépasse les exigences des spécifications ;
- panne byzantine : le système donne des résultats aléatoires.
Classification de la disponibilité
La classification des systèmes en termes de disponibilité conduit communément à 7 classes de non prise en compte (système disponible 90% du temps, et donc indisponible plus d'un mois par an) à ultra disponible (disponible 99,99999% du temps et donc indisponible seulement 3 secondes par an) : ces différentes classes correspondent au nombre de 9 dans le pourcentage de temps durant lequel les systèmes de la classe sont disponibles.
Type Indisponibilité (minutes par an) Pourcentage disponibilité Classe Unmanaged 50.000 (34 jours, 17 heures et 20 min) 90% 1 Managed 5.000 (3 jours, 11 heures et 20 min) 99% 2 Well managed 500 (8 heures 20 minutes) 99,9% 3 Fault tolerance 50 (un peu moins d'une heure) 99,99% 4 High availability 5 minutes 99,999% 5 Very high availability 0,5 (30 secondes) 99,9999% 6 Ultra high availability 0,05 (3 secondes) 99,99999% 7 NB : Une année dure 8760 heures, soit 525.600 minutes.
Les méthodes
- Les composants tolérants aux pannes. Si chaque composant, à son tour, peut continuer à fonctionner lorsque l'un de ses sous-composants est en panne, alors le système entier pourra continuer à fonctionner. Utiliser le véhicule de l'exemple, certaines voitures ont des pneus run flat (pour " roule à plat "), qui contiennent de la gomme solide à l'intérieur pour leur permettre d'être encore utilisés lorsque la chambre à air est crevée. Ils peuvent seulement être utilisés pour une durée limitée et à vitesse réduite, mais c'est une amélioration substantielle par rapport aux pneus traditionnels.
- Redondance. Cela signifie avoir une sauvegarde des composants qui peut prendre la relève dès qu'un composant tombe en panne. Par exemple, des camions larges peuvent perdre un pneu sans grande conséquence. Ils ont tellement de pneus qu'aucun n'est critique (à l'exception des pneus avant, qui sont utilisés pour la direction).
Désavantages
Les avantages d'un système tolérant aux pannes sont évidentes, mais qu'en est-il des désavantages ?
- Interférence avec la détection de panne. Pour conserver l'exemple de la voiture capable de rouler avec un pneu crevé, il n'est peut être pas évident pour un conducteur que sa roue, équipée un système tolérant aux pannes, vient de crever. C'est souvent pris en charge par un système de détection automatique de pannes séparé. Dans le cas du pneu, un détecteur surveille la perte de pression d'air et averti le conducteur. L'alternative est la détection de panne manuelle, comme aller inspecter manuellement tous les pneus à chaque arrêt.
- Réduction de priorité de la correction de pannes. Même si l'administrateur est au courant de la panne, avoir un système tolérant aux pannes est comme réduire l'importance de la réparer. Si la panne n'est pas corrigée, cela pourrait tout de même mener à une défaillance système, lorsque le composant tolérant aux pannes tombe en panne complètement ou lorsque tous les composants redondants ont également cessé de fonctionner.
- Difficulté du test Pour certains systèmes de tolérance aux pannes, tels que des réacteurs nucléaires, il n'y a pas de moyen facile pour vérifier que les composants de sauvegarde sont opérationnels. L'exemple le plus horrible est Tchernobyl, où le système de rafraichissement de secours a été testé en désactivant les systèmes primaire et secondaire. Le système de secours n'a pas fonctionné, provoquant l'explosion et l'échappement du nuage radioactif.
- Coût. Les composants tolérants aux pannes et les composants redondants ont tendance à accroître les coûts. Cela peut être un coût purement économique ou également inclure des mesures autres, telles le poids. Les vols spaciaux habités, par exemple, ont tellement de systèmes redondants et de composants tolérants aux pannes que leur poids est accru drastiquement par rapport aux systèmes non-habités, qui n'ont pas besoin du même niveau de sécurité.
Quand utiliser un système de tolérance aux pannes ?
Fournir un système tolérant aux pannes pour chaque composant n'est généralement pas effectué. Dans de tels cas, le critère suivi peut être utilisé pour déterminer lequel des composants doit être tolérant aux pannes :
- Le composant est-il vraiment critique ? Dans une voiture, la radio n'est pas critique, donc ce composant a moins besoin de tolérance aux pannes.
- Quelle est la probabilité pour que le composant tombe en panne ? Certains composants, tels l'arbre moteur dans une voiture, ne sont pas susceptibles de tomber en panne, et donc un système tolérant aux pannes n'y est pas nécessaire.
- Combien coûte la conception d'un système de tolérance aux pannes ? Embarquer un moteur de voiture redondant, par exemple, est trop cher en termes économiques et en termes de poids pour pouvoir être envisagé.
Un exemple d'un composant qui passe tous les tests est le système d'immobilisation des passagers. Nous ne pensons pas en premier lieu au système d'immobilisation des passagers qu'est la gravité. Si la voiture fait des tonneaux ou est sévèrement freinées à plusieurs G, alors la méthode première du système peut ne pas fonctionner. Immobiliser les passagers pendant un tel accident est critique pour leur sécurité, alors on passe le premier test. Les accidents qui provoquent l'éjection de leurs passagers étaient courant avant les ceintures de sécurité, alors on passe le second test. Le coût d'un système redondant de méthode de blocage des passagers est peu élevé, économiquement et en termes de poids et d'espace, alors on passe le troisième test. Ensuite, ajouter des ceintures de sécurité à toutes les voitures est une excellente idée. D'autres systèmes supplémentaires d'immobilisation des passagers tels les airbags, sont plus chers et pourraient ne pas passer ce test. C'est la raison pour laquelle les véhicules peu cher n'ont pas autant d'airbags que les autres.
Exemples de tolérance aux pannes
La tolérance aux pannes matérielles peut parfois nécessiter que les parties défaillantes soient retirées puis remplacées par les nouvelles pendant que le système reste opérationnel. Un tel système mis en œuvre avec une simple redondance est appelé single point tolerant (à tolérance simple), et représente une vaste majorité de systèmes tolérants aux pannes. Dans de tels systèmes le taux d'échecs moyens entre les pannes doit être suffisamment long pour que les administrateurs aient le temps de réparer l'ancien avant que la sauvegarde ne tombe en panne à son tour. Plus la durée entre les pannes est longue, et plus c'est facile, mais ce n'est pas indispensable dans un système de tolérance aux pannes.
La tolérance aux pannes fonctionne particulièrement bien dans les systèmes informatiques. Tandem Computers ont basés leur business tout entier sur de telles machines, single point tolerant, pour créer leurs systèmes NonStop avec un uptime (temps écoulé depuis le dernier démarrage) mesuré en dizaine d'années.
Différence entre tolérance aux pannes et systèmes avec peu de problèmes
Il existe une différence entre la tolérance aux pannes (système qui fonctionne même lorsqu'une défaillance apparaît) et les systèmes qui ont rarement de problèmes.
Par exemple, la crossbar de Western Electric a un taux de défaillance de deux heures pour quarante ans, et donc hautement résistant aux pannes. Mais lorsqu'une panne apparaît, ils s'arrêtent tout de même, et ne sont donc pas véritablement tolérants aux pannes.
Fiabilité de fonctionnement (ou dependability)
La fiabilité de fonctionnement est la possibilité de se fier aux services délivrés.
Elle dépend de la fiabilité de fonctionnement des composants utilisés.L'origine des pannes
L'origine des erreurs à prendre en compte peut varier :
- Erreurs de conception, de programmation ou de saisie. (design errors)
- Accidents dus à l'environnement. (physical damage)
- Malveillances intentionnelles.
État d'erreur
État d'erreur interne
Une erreur interne, provoquée par les circonstances précédentes, reste interne tant qu'elle n'a pas eu de conséquences sur le fonctionnement externe du système.
Cet erreur peut rester interne longtemps (latence de la faute) mais conduit à court ou long terme à un état d'erreur externe par une défaillance ou panne.
État d'erreur externe
L'état d'erreur externe se manisfeste par des défaillances, des pannes (failures) au niveau du service rendu d'une faute. Le système est en panne si suite à l'un des phénomènes précédents il ne respecte pas l'une de ses spécifications.
En général, seules sont visibles les états d'erreurs externes, comment repérer le problème qui a conduit à la défaillance ?
Évitement des pannes (Fault avoidance)
L'évitement des pannes est l'ensemble des moyens permettant, en amont, d'éviter que le système ne tombe en panne.
Cela passe notamment par :
- Des composants de très bonne qualité (très fiables)
- Une très bonne conception du logiciel, un développement de qualité (génie logiciel)
Voir aussi
Liens externes
- (fr) La tolérance aux pannes dans les systèmes répartis
- (fr) Utilisation de la réflexivité pour la tolérance aux fautes
Catégories : Matériel informatique | Panne informatique | Sûreté de fonctionnement | Machine
Wikimedia Foundation. 2010.